

Você está pronto para compreender um dos maiores segredos por trás do sucesso das arquiteturas baseadas em microserviços? O gerenciamento de dados é o coração pulsante que mantém toda essa independência funcionando com beleza e eficácia!
💾 O que significa gerenciamento de dados em microserviços?
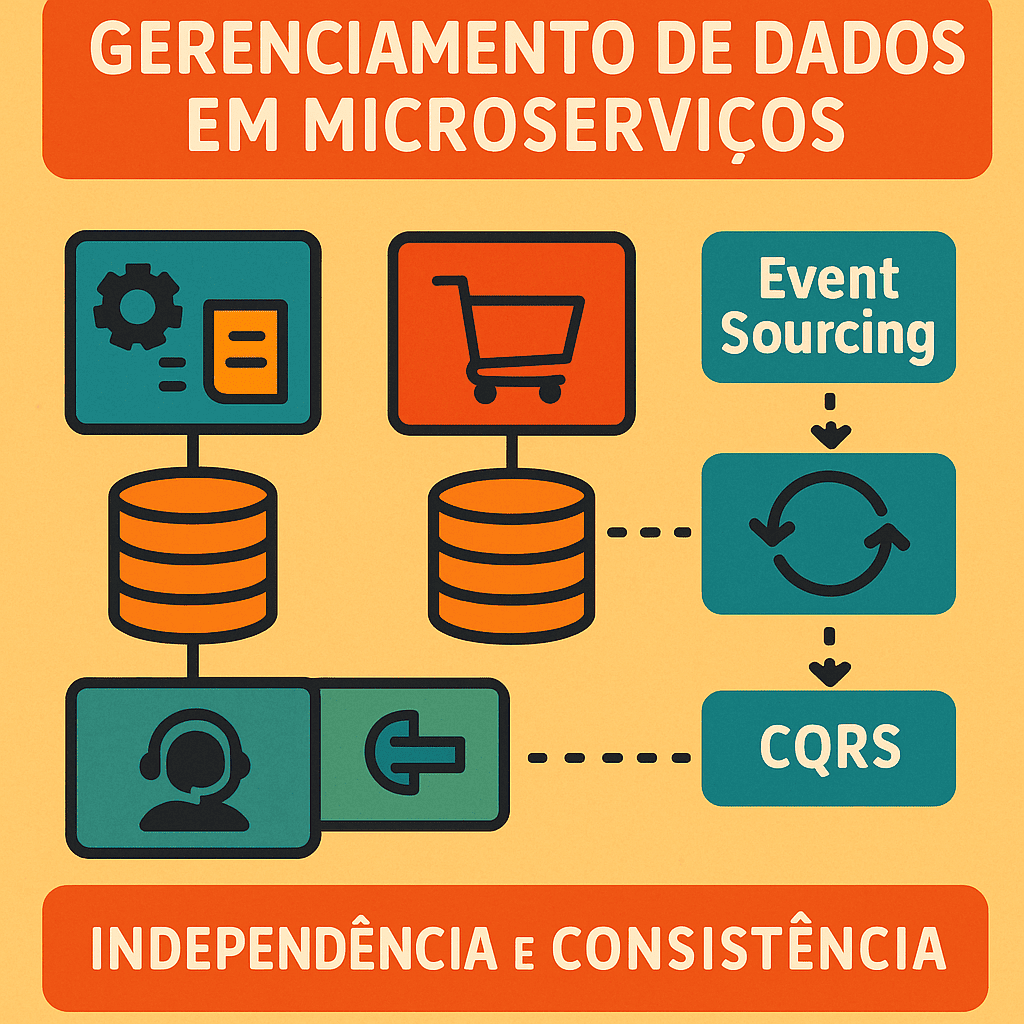
Na arquitetura monolítica tradicional, há uma única base de dados compartilhada por todos os componentes. Nos microserviços, cada serviço gerencia sua própria base de dados independente.
Por que isso é importante?
- Garante independência total dos serviços.
- Permite escolher o tipo de banco de dados ideal para cada serviço.
- Reduz o impacto de falhas (uma falha em um serviço não afeta outros diretamente).
🎯 Emoção: Pense em cada serviço como uma pequena cidade independente, com seu próprio centro de informações, adaptado exatamente às suas necessidades e realidade!
📊 Desafios do Gerenciamento de Dados Distribuídos
Claro que tamanha independência traz grandes desafios:
- Consistência Eventual: Com bancos de dados separados, a consistência instantânea entre eles não é possível. É necessário gerenciar consistência eventual de forma inteligente.
- Transações Distribuídas: Transações que envolvem múltiplos serviços tornam-se complexas. É preciso estratégias específicas para coordená-las.
🛡️ Emoção prática: Aceitar e dominar esses desafios é como aprender a navegar em mares turbulentos, sempre com confiança e precisão!
🛠️ Padrões Essenciais para Gerenciar Dados em Microserviços
Vamos conhecer três estratégias poderosas:
1️⃣ Database per Service (Banco por Serviço)
Cada serviço tem seu banco de dados dedicado.

Benefícios:
- Máxima independência.
- Flexibilidade para escolher a tecnologia mais apropriada.
Cuidados:
- Garantir consistência eventual com outros serviços é vital.
2️⃣ Event Sourcing
Nesse padrão, você armazena uma sequência de eventos (ações) ao invés do estado atual do dado. O estado é reconstruído a partir desses eventos.
Benefícios:
- Histórico completo de mudanças.
- Facilita depuração e auditoria.
Desafios:
- Maior complexidade inicial.
3️⃣ CQRS (Command Query Responsibility Segregation)
Divide o modelo de dados em duas partes: uma para escrita (Comandos) e outra para leitura (Consultas).
Benefícios:
- Melhora desempenho e escalabilidade.
- Otimiza cada lado para sua função específica.
Desafios:
- Maior complexidade e esforço inicial.
🌟 Emoção: Esses padrões são ferramentas poderosas que colocam você no controle total sobre seus dados, permitindo decisões estratégicas e inovadoras!
🎯 Como Escolher o Padrão Ideal?
A escolha depende das necessidades específicas de cada microserviço:
- Precisa de flexibilidade máxima? Database per Service!
- Quer histórico completo e auditoria facilitada? Event Sourcing!
- Necessita alta performance em leitura e escrita? CQRS!
🏆 Desafio da Quinta Lição
Para consolidar o aprendizado, faça o seguinte exercício:
- Escolha um domínio (exemplo: rede social, sistema financeiro ou plataforma de streaming).
- Defina quais serviços teriam bases independentes e por quê.
- Identifique onde Event Sourcing ou CQRS poderiam ser aplicados e justifique emocionalmente suas decisões.
Esse exercício vai fortalecer muito seu entendimento e confiança!

